https://data.kma.go.kr/climate/RankState/selectRankStatisticsDivisionList.do?pgmNo=179
공공 데이터 포털에 가서 원하는 데이터를 csv나 excel로 다운로드 받을수 있음
기상자료개방포털[기후통계분석:통계분석:조건별통계]
중부(26) 서울경기: 서울(108), 인천(112), 수원(119), 강화(201), 양평(202), 이천(203) 강원영동: 속초(90), 강릉(105), 태백(216) 강원영서: 철원(95), 대관령(100), 춘천(101), 원주(114), 인제(211), 홍천(212) 충북:
data.kma.go.kr

import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
print(data) # 객체의 주소가 출력됨 <_csv.reader object at 0x7ff327763850>
f.close()출력값: csv 파일의 주소가 출력됨
<_csv.reader object at 0x7ff327763850>
데이터를 한줄한줄 출력하고 싶을때
import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
for row in data: #data를 한줄씩 읽는다.
print(row)
print(data) # 객체의 주소가 출력됨 <_csv.reader object at 0x7ff327763850>
f.close()출력값
스트리밍 출력 내용이 길어서 마지막 5000줄이 삭제되었습니다.
['2004-07-21', '108', '26.8', '24.1', '31.8']
['2004-07-22', '108', '27.4', '24.1', '32']
['2004-07-23', '108', '28.3', '24', '33.2']
['2004-07-24', '108', '27.6', '23.7', '30.8']
['2004-07-25', '108', '25.4', '22.6', '28']
['2004-07-26', '108', '26.5', '23.8', '29.2']
['2004-07-27', '108', '27.6', '24.7', '30.2']
['2004-07-28', '108', '28.7', '26', '32.7']
['2004-07-29', '108', '28.9', '24.1', '33.2']
['2004-07-30', '108', '29.2', '25.2', '33.4']
['2004-07-31', '108', '29.9', '24.7', '34.5']
['2004-08-01', '108', '29.4', '25.3', '34.2']
['2004-08-02', '108', '28.3', '23.7', '33.2']
['2004-08-03', '108', '28.8', '25.7', '32.7']
['2004-08-04', '108', '28.5', '23.2', '32.9']
['2004-08-05', '108', '27.6', '23.8', '32.7']
['2004-08-06', '108', '28.3', '24.7', '32.9']
['2004-08-07', '108', '28.5', '26.2', '32.4']
['2004-08-08', '108', '27.8', '26.1', '32']
['2004-08-09', '108', '28.6', '25', '33']
['2004-08-10', '108', '30.2', '25.2', '36.2']
['2004-08-11', '108', '30.4', '25.6', '35.7']
['2004-08-12', '108', '29.6', '25.6', '34.7']
지정된 열만 출력하고 싶을때:
import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
for row in data: #data를 한줄씩 읽는다.
print(row[4]) #최고기온 출력
print(data) # 객체의 주소가 출력됨 <_csv.reader object at 0x7ff327763850>
f.close()출력값:
스트리밍 출력 내용이 길어서 마지막 5000줄이 삭제되었습니다.
31.8
32
33.2
30.8
28
29.2
30.2
32.7
33.2
33.4
34.5
34.2
33.2
32.7
32.9
32.7
32.9
32.4
32
33
36.2
csv 파일의 데이터가 string인데 값을 실수로 형변환을 하고 싶을때:
import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
next(data)
for row in data: #data를 한줄씩 읽는다.
row[-1] = (float(row[-1])) #최고기온 출력
print(row)
print(data) # 객체의 주소가 출력됨 <_csv.reader object at 0x7ff327763850>
f.close()
하지만 ValueError: could not convert string to float: 라는 에러가 뜬다.
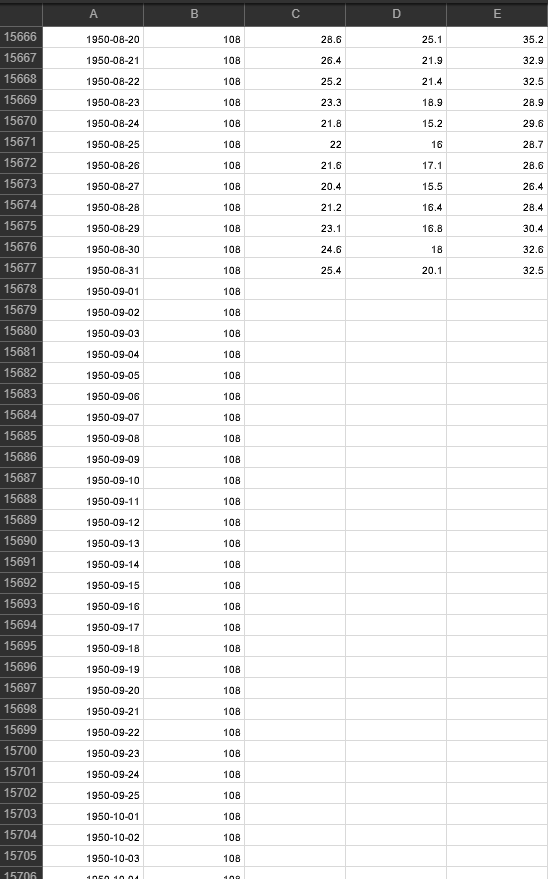
확인해보면 1950-09-01 부터 마지막 열에 데이터가 공백으로 들어가서 string to float가 아니라 null to float라서 당연히 에러가 뜬다.
from contextlib import nullcontext
import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
next(data)
for row in data: #data를 한줄씩 읽는다.
if row[-1] == "": #공백이 생기면 에러가 난다... 그래서 마지막 배열에 값이 비어있을때 000으로 대체
row[-1] = 000
row[-1] = (float(row[-1])) #최고기온 출력
print(row)
print(data) # 객체의 주소가 출력됨 <_csv.reader object at 0x7ff327763850>
f.close() if row[-1] == "": #공백이 생기면 에러가 난다... 그래서 마지막 배열에 값이 비어있을때 000으로 대체
row[-1] = 000
라는 코드 추가
스트리밍 출력 내용이 길어서 마지막 5000줄이 삭제되었습니다.
['2004-07-21', '108', '26.8', '24.1', 31.8]
['2004-07-22', '108', '27.4', '24.1', 32.0]
['2004-07-23', '108', '28.3', '24', 33.2]
['2004-07-24', '108', '27.6', '23.7', 30.8]
['2004-07-25', '108', '25.4', '22.6', 28.0]
['2004-07-26', '108', '26.5', '23.8', 29.2]
['2004-07-27', '108', '27.6', '24.7', 30.2]
['2004-07-28', '108', '28.7', '26', 32.7]
['2004-07-29', '108', '28.9', '24.1', 33.2]
['2004-07-30', '108', '29.2', '25.2', 33.4]
['2004-07-31', '108', '29.9', '24.7', 34.5]
['2004-08-01', '108', '29.4', '25.3', 34.2]
['2004-08-02', '108', '28.3', '23.7', 33.2]
['2004-08-03', '108', '28.8', '25.7', 32.7]
['2004-08-04', '108', '28.5', '23.2', 32.9]
['2004-08-05', '108', '27.6', '23.8', 32.7]
['2004-08-06', '108', '28.3', '24.7', 32.9]
['2004-08-07', '108', '28.5', '26.2', 32.4]
['2004-08-08', '108', '27.8', '26.1', 32.0]
['2004-08-09', '108', '28.6', '25', 33.0]
['2004-08-10', '108', '30.2', '25.2', 36.2]
['2004-08-11', '108', '30.4', '25.6', 35.7]
['2004-08-12', '108', '29.6', '25.6', 34.7]
['2004-08-13', '108', '28.7', '26', 32.7]
['2004-08-14', '108', '26.3', '24', 29.2]
['2004-08-15', '108', '26.7', '22.8', 31.0]
['2004-08-16', '108', '25', '21.5', 29.1]
['2004-08-17', '108', '23.1', '21.1', 26.2]
['2004-08-18', '108', '23.2', '22', 25.0]
['2004-08-19', '108', '21.8', '19.1', 25.3]
['2004-08-20', '108', '23.5', '20.5', 26.8]잘 출력이 됨!!!
최고기온 날짜및 온도 출력
import csv
f = open('/content/drive/MyDrive/Colab Notebooks/기온분석/seoul.csv', 'r', encoding = 'cp949')
data = csv.reader(f, delimiter= ',')
temp = -999
max_date = ''
next(data)
for row in data: #data를 한줄씩 읽는다.
if row[-1] == '':
row[-1] = -999
row[-1] = (float(row[-1]))
if temp < row[-1]:
max_date = row[0]
temp = row[-1]
f.close()
print(max_date) #최고기온 날짜
print(temp) #최고기온 날짜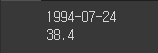
참고문헌
https://thebook.io/007029/part01/unit03/03-01/
모두의 데이터 분석 with 파이썬: 3 파이썬 코드로 구현하기 - 1
thebook.io